on
Convolutional Network and Models
Convolutional Network를 사용한 여러 모델 중 내가 참여했던 자율차 프로젝트에서 최종 프로그램에 개발자 분들이 실제로 쓴 것(Inception v1)과 프로젝트 시작 전에 내가 궁금해서 알아봤던 것(YOLO)만 더 자세히 정리해 보았다. (그래봤자 인트로만…) 표지판 분류를 위한 모델이므로 모두 이미지 분류 모델이다.
Convolutional Network
Convolutional networks for images, speech, and time series, 1995
Convolutional networks and applications in vision, 2010
Model Using CNN
- Inception
- YOLO (You Only Look Once)
Inception
Going deeper with convolutions, 2015
주 특징
- 네트워크 내부에서 컴퓨팅 리소스의 활용도를 향상시켰다.
배경
- DNN에서 네트워크의 깊이, 넓이 등의 사이즈를 늘리는 것은 모델의 성능을 향상시키는 가장 확실한 방법이다.
- 그러나 이 간단한 해결책은 문제가 있다.
- 큰 네트워크 모델은 parameter의 개수가 많으므로 학습 데이터가 한정적인 경우 모델의 overfitting이 더 많이 일어난다. 그리고 양질의 데이터는 많이 모으려면 비싸다.
- 네트워크가 커지면 커질수록 리소스 사용량은 어마어마하게 많아진다. 그리고 딥 비전 네트워크의 구조상 네트워크가 커지면서 추가되는 대부분의 메모리는 유효한 값을 저장하지 못하고 낭비된다. (vanishing)
- 이 두 문제를 해결하는 근본적인 방법은 컨볼루션의 내부에서도 fully connected 구조보다는 sparsely connected 구조를 사용하는 것이다.
- 만약 크고 아주 희소한 DNN에서 데이터셋의 확률 분포를 나타낼 수 있다면
- 각 레이어별로 최적화된 네트워크 토폴로지가 구성될 수 있다.
- 어떻게? 마지막 레이어의 activation 의 상관관계 통계를 분석하여
- 그리고 상관관계가 큰 아웃풋을 이용해 뉴런을 클러스터링하여
- 그러나 실제 컴퓨터 구조상 uniform하지 않은 희소 데이터를 계산하는 것은 비효율적이다. 또한, non-uniform sparse model은 더 정교한 엔지니어링과 컴퓨터 구조가 필요하다. 컨볼루션 넷은 전통적으로 random and sparse connection 으로 overfit을 피하려고 했으나, 병렬 컴퓨팅에 최적화하기 위해 다시 full connection으로 돌아오고 있었다.
- 그래서 희망이 있느냐,
- 희소한 매트릭스를 상대적으로 덴스한 서브매트릭스로 클러스터링 하는 것은 희소 행렬 곱셈에서 실용적인 성능을 제공한다는 것은 이미 알려져 있었다.
- 따라서 그 구조를 비전 네트워크에 적용한다.
구조
Kiho Hong. Google Inception Model.: Inception v1 - v4, Inception-resnet의 구조까지 한 번에 정리한 글
구현
Tensorflow 이용: inception_v1.py, inception_v1_test.py
YOLO (You Only Look Once)
You only look once: Unified, real-time object detection, 2016
Yolov3: An incremental improvement, 2018
주 특징
- Frame object detection을 하나의 regression problem으로 보았다. 즉, 공간적으로 분리된 박스들은 각 클래스로 구분될 확률들과 연관이 있다고 보고, 이 사이의 관계를 하나의 회귀 모델로 보았다.
- 모든 detection pipeline이 싱글 네트워크이기 때문에 detection 성능이 끝에서 끝까지 최적화되어있다.
- 속도가 아주 빨라서 이미지를 45 fps의 real-time으로 처리할 수 있다.
- 최신의 다른 detection system과 비교해서, localization 에러는 더 많으나 배경에 의해 구분을 실패하는 경우는 더 적다.
배경
- 사람은 이미지를 한 번 흘낏 보고는 어떤 물체가 있는지, 어디에 있는지, 그리고 어떻게 상호작용하는지를 즉시 안다. 이런 빠르고 정확한 시각 시스템 덕분에 인간은 자동차 운전과 같이 복잡한 행동을 조금만 생각하고도 수행할 수 있다.
- 빠르고 정확한 비전 오브젝트 디텍션 알고리즘이 있다면 특별히 비싼 센서가 없어도 컴퓨터가 자동차를 운전할 수 있게 해 줄 것이다.
구조
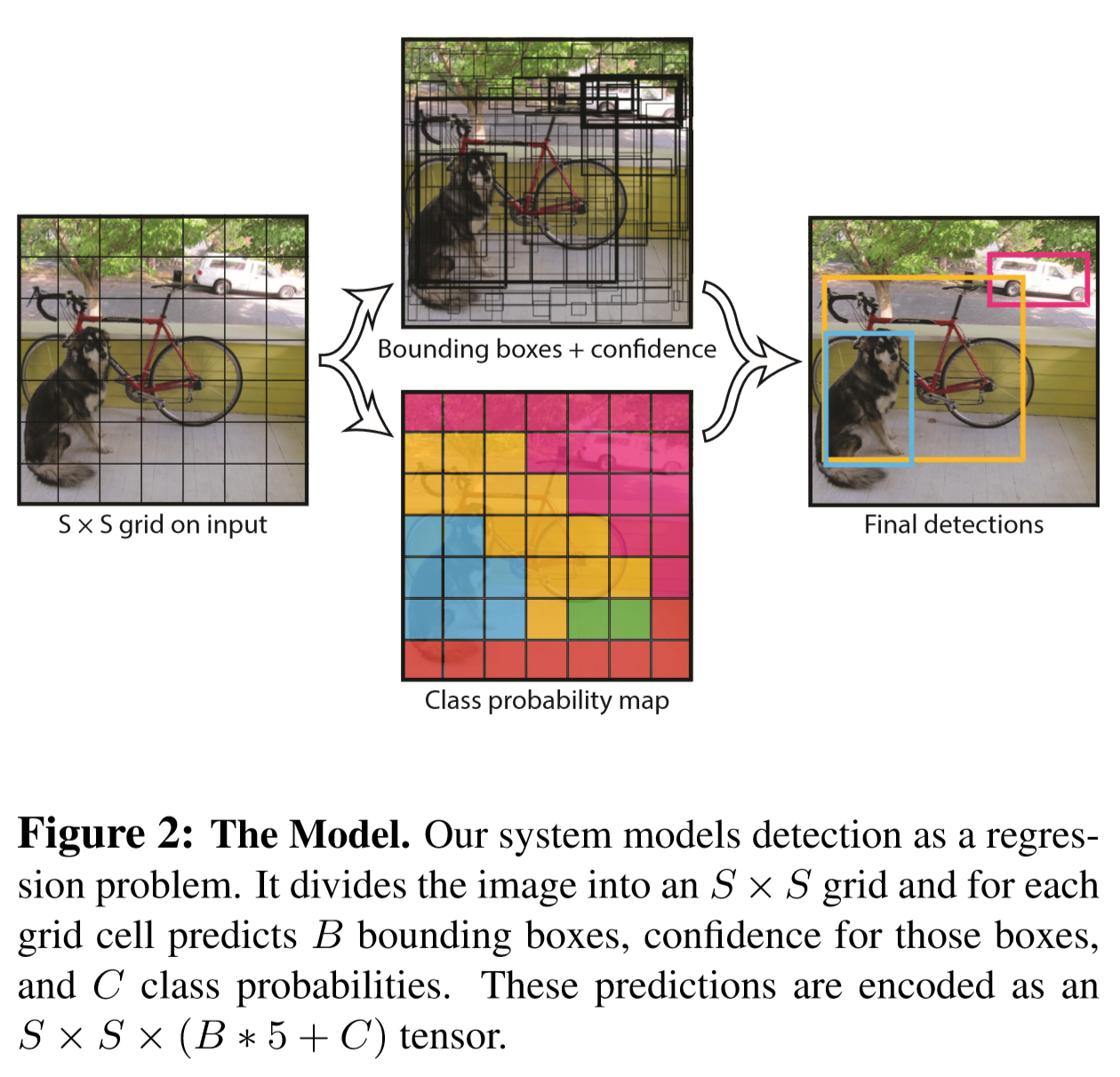
- grid cell: 전체 이미지를 $S * S$로 나눈 것
- bounding box: 각 grid cell은 $B$개의 bounding box를 예측한다
- 각 bounding box는 다음과 같은 5개의 값을 예측한다: $x, y, w, h$, $confidence$
- 이런 방식으로 이미지 전체를 하나의 회귀 문제로 만들었다.
- 네트워크의 구조는 GoogLeNet(Inception의 한 종류)에서 영감을 얻었다고 한다.

구현
Darknet 이용: yolo.c
참고 문헌
LECUN, Yann, et al. Convolutional networks for images, speech, and time series. The handbook of brain theory and neural networks, 1995, 3361.10: 1995.
LECUN, Yann, et al. Convolutional networks and applications in vision. In: ISCAS. 2010. p. 253-256.
SZEGEDY, Christian, et al. Going deeper with convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2015. p. 1-9.
Kiho Hong. Google Inception Model.
REDMON, Joseph, et al. You only look once: Unified, real-time object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. p. 779-788.
REDMON, Joseph; FARHADI, Ali. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018.
Appendix
YOLO의 원리 (논문 대충 읽고 정리한)
YOLO는 전체 이미지에 대해 globally 추론한다. 즉, 특정 부분의 이미지를 자르지 않고 전체 이미지를 받으면 모든 class에 대한 bounding box를 일제히 예측한다.
Input image를 $S \times S$ 의 grid로 나눈다. 만약 오브젝트의 중심이 grid cell의 중심에 들어오면, 그 grid cell은 오브젝트를 감지했다고 반응할 것이다.
각 grid cell은 $B$ 개의 bounding box와 각 box의 confidence score를 예측한다.
confidence score는 box가 오브젝트를 포함하고 있는 것을 모델이 얼마나 확신하는지와 그 예측된 box에 대해 얼마나 정확하게 생각하는지를 반영한다.
\[Confidence = Pr(Object) \times IOU_{pred}^{truth}\]$IOU_{pred}^{truth}$: Intersection over uinion between the predicted box and the ground truth
만약 cell 안에 아무런 오브젝트가 없다면, confidence는 zero가 된다.
그렇지 않다면, confidence는 예측한 box와 실제값 truth 사이의 intersection over union과 같아야 한다.
각 bounding box는 5개의 prediction을 가지고 있다: $x, y, w, h, confidence$
각 grid cell은 $C$개의 그 클래스일 조건부 확률을 예측한다.
\[Pr(Class_i \mid Object)\]이 확률은 어떤 grid cell이 object를 포함하고 있는 조건 하의 확률이다. 각 grid cell마다 한 세트의 class probability를 예측한다. bounding box의 개수 $B$와는 관련이 없다.
이제 필요한 모든 것들을 예측했으니, 각 box별 class-specific confidence score를 계산할 수 있다.
\[Pr(Class_i \mid Object) \times Pr(Object) \times IOU_{pred}^{truth}\]즉, 그 클래스가 그 박스에 나타날 확률과 그 예측된 박스가 오브젝트에 얼마나 잘 맞는지 둘 다를 의미한다.