on
Paper Reading: [Managing Deadline Miss Ratio and Sensor Data Freshness in Real-Time databases]
올해 5월 자율차 대회를 끝내고 아쉬운 점 중에서 ‘데이터를 실시간으로 더 잘 다룰 수 있게 프로그램 구조를 짰으면’하는 생각이 있었다(관련 글). 최근에 나는 이런 고민에 대한 해결의 한 방법으로 관련 분야가 Real-Time Database라는 이름으로 연구되어왔다는 조언을 들었고, 다음 논문을 훑어보았다. Kang, K-D., Sang Hyuk Son, and John A. Stankovic. “Managing deadline miss ratio and sensor data freshness in real-time databases.”
이 페이퍼는 real-time database의 모델을 소개하며 이 모델의 서비스 퀄리티를 보장하는 데에 사용할 수 있는 측정법을 소개하고 있다. 또한 이 측정법을 이용한 실시간 데이터베이스를 관리하는 방법을 제안해 시뮬레이션을 돌려 보았다고 한다. 페이퍼의 내용이 길기에 일단 문제 상황을 정의하는 부분을 아래에 정리해 보았다.
Real-Time Databases
요구 사항
- 트랜잭션이 데드라인 안에 수행되어야 한다.
- 트랜잭션이 현실의 현재 상황을 반영해야 한다.
- 너무 과거의 데이터를 이용한 쿼리 처리는 의미가 없는 분야에서 주로 사용된다. (online stock trading, agail manufacturing, sensor data fusion, traffic control…)
- 이를 fresh sensor data를 사용한다고 표현한다.
어려움
- 트랜잭션이 요구하는 데이터 종류의 패턴이 유동적이다.
- 어떤 데이터를 먼저 업데이트할 것인가의 이슈가 있다.
- 트랜잭션 데드라인을 맞추는 것과 데이터의 신선도를 유지하는 것은 상충되는 목표이다.
- 센서 데이터가 업데이트되기를 기다렸다가 쿼리를 처리하는 것은 데드라인을 놓치는 비율을 늘릴 수 있다. 반대로, 유저 요청을 먼저 처리하는 방법은 데이터의 신선도를 만족하지 못할 수 있다.
QMF
- a QoS management architecture for deadline Miss ratio and data Frechness
- Flexible Freshness Management
QMF는 데이터베이스 관리자에게 miss ratio와 data freshness를 적절히 측정하고 실시간 데이터베이스가 적용된 어플리케이션을 적절하게 관리할 수 있게 하는 QoS(Quality of Service) 파라미터들을 제공한다.
- Main memory database model
- CPU를 메인 시스템 리소스로 사용하는 데이터베이스 모델
- real-time database에 널리 사용되고 있는 모델 (memory 값이 싸졌고, 성능이 좋기 때문)
Transactions
Sensor updates
- Write-only transactions
- 현실의 상황을 반영한다
User transactions
- Read sensor data
- 유저 입장에서 데이터가 필요할 때 읽으려 하는 요청
- Read / Write non-sensor data
- PIN number와 같이 시간 제약과 관계 없는 데이터
- Execute arithmetic / logical operations
- 현실 상황을 반영한 연산 요청
Firm Deadline Semantics
- 데드라인 내에 끝난 트랜잭션의 값만 데이터베이스에 추가한다.
많은 실시간 데이터베이스에서 흔하게 사용되는 특징이다. 변경 사항을 늦게 저장하는 것은 상품의 질이나 시스템 리소스에 좋지 않은 영향을 끼치는 상황이 있다. 현실의 현재 상황을 제대로 반영하지 못했기 때문이다. 따라서 이러한 특징을 고려한다.
Deadline Miss Ratio
\[MR = 100 \times {\#Trady / (\#Trady + \#Timely)} (\%)\]#Trady 는 데드라인을 놓친 트랜잭션의 개수, #Timely는 데드라인을 맞춘 트랜잭션의 개수이다.
Metrics
평균 miss ratio와 같이 긴 시간을 보는 측정법은 실시간 데이터베이스의 다이나믹한 환경에 적용하기에 적합하지 않다. 따라서 overshoot과 settling time을 다음과 같이 정의한다.
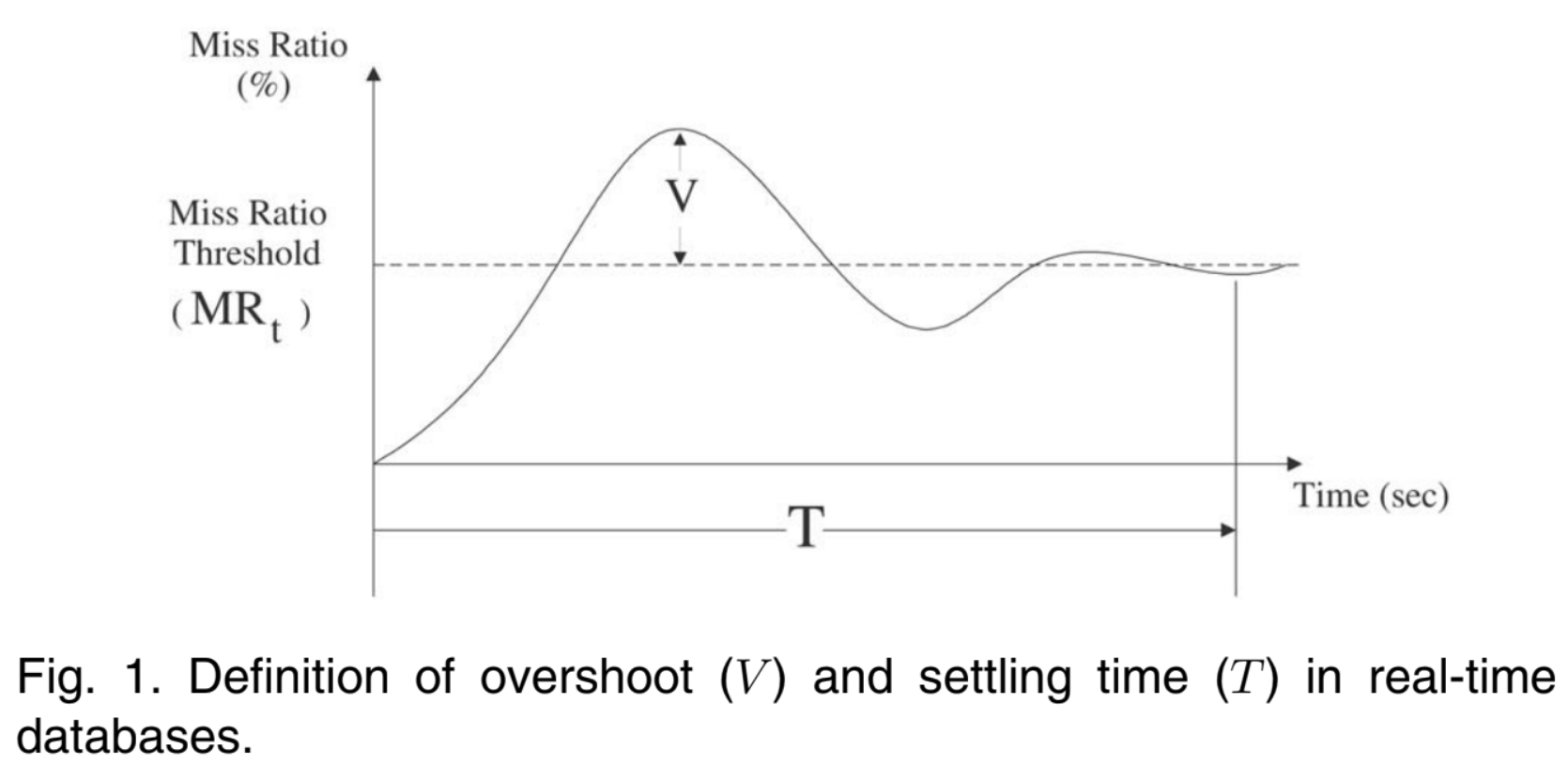
Overshoot
시간이 지남에 따라 미스 비율이 요동칠 수 있으며, 데이터베이스는 이 미스 비율이 threshold를 넘지 않도록 제어하려고 노력할 것이다. Overshoot은 이 일시적인 상황에서 threshold를 넘은 가장 큰 미스 비율 $V$로 정의된다.
Settling time
Settling time은 overshoot에서 decay로 갈 때까지 걸린 시간 $T$로 정의된다. $T$ 시간이 지난 후 미스 비율이 $[0, MR_{t} + 0.01 \times MR_{t}]$ 범위 안에 있는 steady 상태에 진입해야 한다.
Management Architecture
본 논문은 위와 같이 실시간 문제 상황에서의 데이터베이스에서 QoS 매니지먼트를 위해 Control Loop를 사용하였다(마치 실내 온도나 자동차의 속도를 제어하는 것처럼). 3, 4장은 관련 metric을 정의하고 QoD(database freshness)를 관리하는 정책을 제안하였고, 5장부터는 control loop의 전체 아키텍처 설명이, 6장은 시뮬레이션 실험 내용이 서술되어 있다. 해당 내용은 본 글에서는 정리하지 않는다.
정리하며
생각보다 내용이 많아서 내가 필요해 보이는 부분만 일단 정리해 두는 식으로 읽어 보았다. 문제 상황을 기존의 제어 이론을 비슷하게 적용할 수 있도록 수학적으로 서술하는 과정이 인상깊었다. 제어 이론은 자율차 대회 준비할 때 동아리에서 기계과랑 전기과 사람들을 통해서 어깨너머로 들은 내용밖에 몰랐기 때문에, 기계나 전기 제어에서만 쓰인다고 생각했던 해결 방법이 real-time database처럼 하드웨어와 거의 관련이 없는 분야에서도 적용될 수 있다는 것이 신기했다. 문제를 잘 해결하려면 문제를 잘 정의하는 것이 중요하다는 생각이 다시 한 번 든다. 그리고 이런 방식으로 문제를 잘 정의한 논문을 더 읽어본다면 내가 겪었던 문제 상황을 수학적으로 서술하는 데 도움을 받을 수 있을 것 같다는 생각이 들었다.