on
Paper Reading: [Learning to Drive in a day]
나는 지난 7월에 Learning to drive in a day 라는 포스트를 보았다. 페이스북 Reinforcement Learning KR 그룹의 공유 게시글을 통해서 알게 되었는데, 저 포스트에 있는 동영상을 보고 깜짝 놀라서 저장해 뒀었다. 그리고 이번 주말에는 이 논문을 읽고 정리해 보기로 했다. Kendall, Alex, et al. “Learning to Drive in a Day.” (2018) 이 논문은 end-to-end 강화학습 딥러닝을 현실의 자동차에 적용해 자동차가 스스로 운전하도록 학습시켰고 결과가 좋았다고 말하고 있다.
방법
문제 정의
자동차가 운전하는 환경을 MDP 문제로 변환하기 위해 다음과 같이 정의했다고 한다.
State Space
이 논문이 제시하는 환경을 정의하는 방법은 아주 간단하다. 보통 자율차에는 아주 많은 종류의 센서가 사용됨에도 불구하고 이 팀은 하나의 카메라만을 사용했다. 이미지 원본을 사용할 수도 있지만, Variational Autoencoder(VAE)와 같은 이미지 압축 기술을 적용한 실험도 진행하였다. 또한 자동차의 주행 속도와 조향각을 컨트롤러부터 전달받을 수 있는데 이 값도 학습에 사용한다.
특히, RNN등의 네트워크를 사용하면 과거의 state도 고려한 환경을 정의할 수 있으나 본 실험에서는 그냥 해당 시점의 관찰 그 자체로도 충분히 근사한 결과를 얻을 수 있을 것으로 생각하고 환경을 정의하였다.
- Monocular camera image (compressed representation using VAE)
- Vehicle speed
- Steering angle
- and Not use RNN etc. (use the observation itself)
Action Space
스로틀 액션을 정의하는 방법은 여러 가지가 있는데, 이산적으로 on/off를 줄 수도 있고, 연속적으로 값을 줄 수도 있으며, 단순히 차량의 속도를 지정해주어서 그 속도까지 제어하도록 할 수도 있다. 이 팀은 3D 시뮬레이션을 통해 action space를 연속 공간으로 주는 것이 낫다는 것을 확인했다. 따라서 다음과 같은 2-dimensional action space를 정의했다.
- Steering angle in the range [-1, 1]
- Speed setpoint in km/h
Reward Function
차선 중앙과 같이 차량이 따라가야 할 길을 미리 지정해주어서 reward function을 정의하는 방법이 있겠으나, 이는 사람이 직접 데이터를 제공해주어야 한다는 점에서 한계가 있다. 따라서 이 팀은 그런 방법 대신, 자동차가 앞으로 가면 좋은 것이고, 차가 가지 못하는 길을 가서 에피소드가 끝나는 경우는 나쁜 것이라는 점을 고려했다. 따라서 규칙을 위반해서 멈추기 전까지 이동한 평균 거리를 보상으로 정의했다.
- Average distance travelled before an infraction
네트워크 모델
DDPG (Deep Deterministic Policy Gradients) 모델을 이용했다.
Bellman Equation
\[Q(s_t, a_t) = r_{t+1} + \gamma(1 - d_t) Q(S_{t+1}, \pi(s_{t+1}))\]정책은 $\pi: \mathcal{S} \to \mathcal{A}$ 로 정의되며, $\pi(s) = argmax_{a}Q(s, a)$를 만족하도록 선택된다. 즉, $Q$값이 가장 크게 되는 action을 선택하는 것이다.
$Q: \mathcal{S} \times \mathcal{A} \to \mathbb{R}$로 정의되며, 시점 $t$에서 상태 $s_t$와 액션 $a_t$가 주어지면 $Q$값을 얻을 수 있다. 현재 시점에서의 $Q$값은 어떤 정책 $\pi$를 선택하고 한 시점 이후의 $Q$값에 discount factor $\gamma$를 곱한 뒤 $t+1$시점에서의 실제 보상값 $r_{t+1}$을 더한 것과 같다. 이 때 두 번째 항에 곱해진 $(1-d_t)$항은 done 플래그를 받은 경우 미래에 대한 $Q$값이 없으므로 없애주는 역할을 한다.
Using Replay Buffer
한 시점마다 받는 tuple은 $(s_t, a_t, r_{t+1}, d_{t+1}, s_{t+1})$이다. 그러나 매 시점 이 튜플을 통해 $Q$값을 학습시키는 것은 시간 관점에서 너무 조밀하다. 따라서 replay buffer를 이용해 튜플들을 보관해뒀다가 일정 이상 쌓인 후 버퍼에서 샘플링을 한 뒤 그 튜플을 가지고 학습을 진행시킨다.
Exploration Policy: Ornstein-Uhlenbeck Process Noise
테스트가 아닌 트레이닝 시에는 시점 $t$에 정책을 선택할 때 단순히 $Q$값을 가장 크게 하는 액션을 고르기만 하면 학습이 잘 되지 않을 수 있다. 따라서 그 값에 noise $x_t$를 추가한다.
\[x_{t+1} = x_t + \theta (\mu - x_t) + \sigma \epsilon_t\]$\theta, \mu, \sigma$는 모두 실험을 통해 조정해주어야 하는 hyperparameter이다. $\epsilon_t$는 확률변수이며, $iid$ 하게 $N(0, 1)$을 따른다.
구조
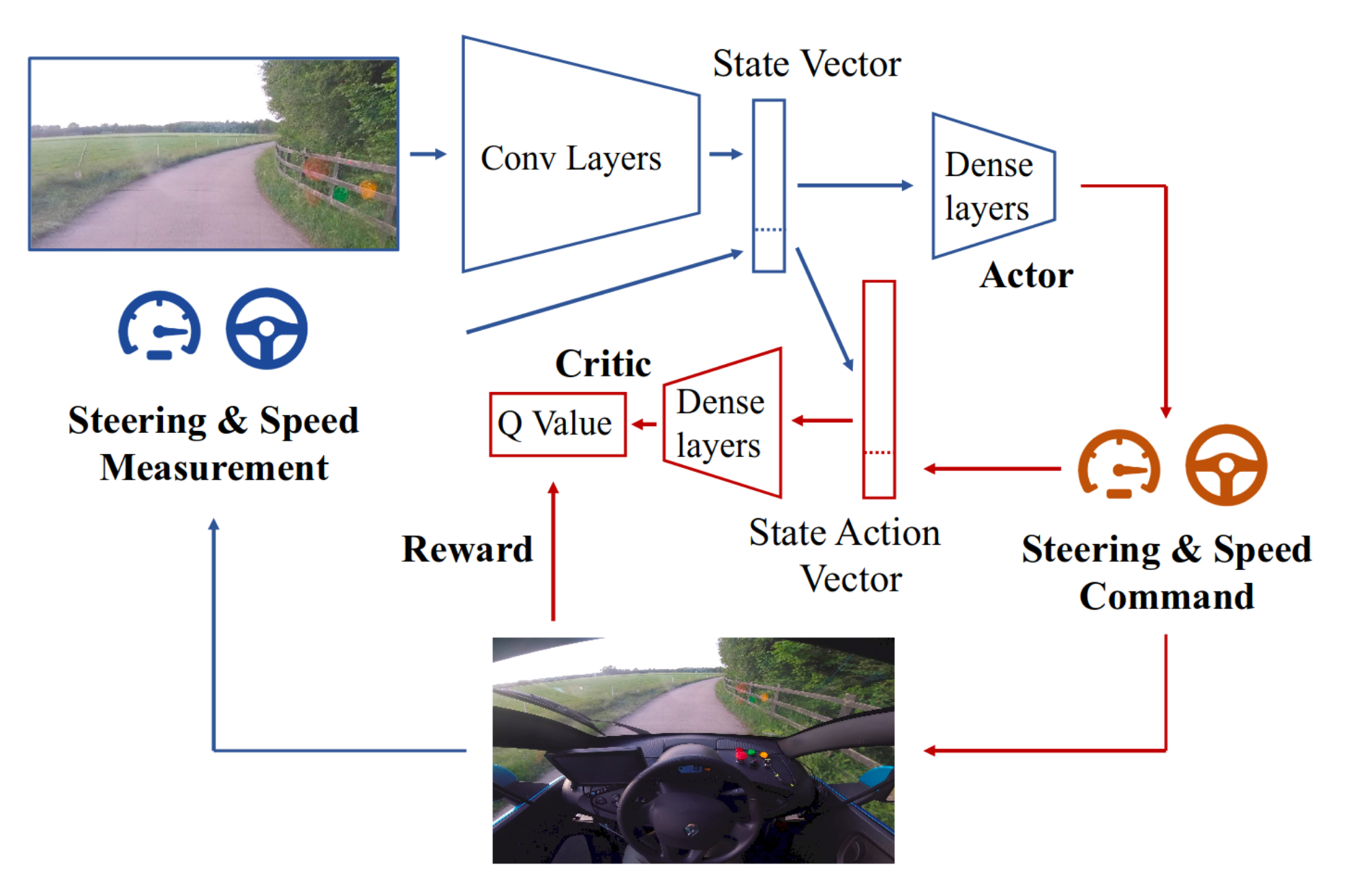
- 4 convolutional layers
- 3 $\times$ 3 kernels
- stride of 2
- 16 feature dimensions
- State vector (concatenated, from conv layers and control measurement)
- One fully-connected layer with feature size 8
실험 방법
시뮬레이션을 통해 파라미터 조정을 마친 뒤 실차 실험을 진행했다고 한다. 실험 시에는 다음과 같이 네 가지 플래그를 주어 전체 학습 워크플로우를 구성했다.
train: 에피소드를 진행하며 노이즈가 추가된 정책을 통해 모델을 조정한다.
test: 최적 정책으로 에피소드를 진행한다.
undo: 방금 있었던 train or test task를 되돌린다.
done: 실험을 끝낸다.
결과
시뮬레이션
이 팀은 Unreal Engine 4를 이용해 3D 운전 시뮬레이터를 개발했다. 시뮬레이션 환경은 다양한 날씨와 도로 질감 등을 지원한다. 시뮬레이션을 통해 여러 hyperparameter들을 조정하고, 가장 효율적인 값들을 찾아내었다.
- future discount factor: 0.9
- noise half-life: 250 episodes
- noise parameters
- $\theta$: 0.6, $\sigma$: 0.4
- optimisation steps between episodes: 250
- batch size: 64
- gradient clipping 0.005
실제 차량 실험
실차 실험 때는 시뮬레이션에서 찾은 가장 효율적이었던 파라미터들을 그대로 사용했다. 모든 컴퓨팅은 NVIDIA Drive PX2 한 대를 사용했으며, 카메라는 가운데에서 전방을 바라보는 한 대만을 사용했다.
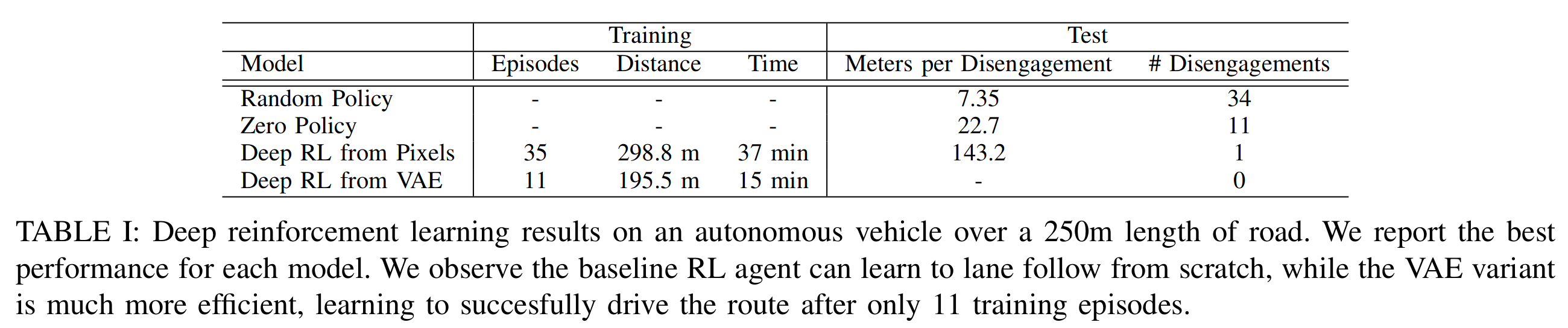
차량의 속도가 10km/h를 넘거나, 차량에 타고 있는 사람이 차가 잘못된 방향으로 갈 때 직접 멈추면 에피소드가 끝나도록 했다고 한다. 하나의 에피소드가 끝나면 차량을 다시 가운데로 정렬시키고 다음 에피소드를 진행하도록 했다. 다음은 네 가지 방법으로 250m의 도로를 달리게 한 실험의 결과표이다. VAE(이미지 압축 기술)을 적용하여 학습시킨 방법은 적은 에피소드를 학습하고 나서도 한 번도 틀리지 않고 250m를 완주한 것을 볼 수 있다.
정리하며
아직 공부를 덜 해서 DDPG가 DQN이랑 어떻게 다른지 잘 알지 못한다. 또한 구조도 잘 이해하지 못했는데, 왜 그리고 어떻게 conv net을 actor와 critic이 공유하는 것인지 잘 모르겠다. 그래서 이 논문을 완전히 이해했다는 생각이 들지 않는다.
그러나 문제 정의는 강화학습을 처음 접한 나도 쉽게 이해할 수 있을 만큼 간단하게 느껴졌다. 이렇게 비교적 간단한 문제 정의만으로 재미있는 결과를 이끌어냈다는 점이 참 흥미롭다고 생각한다.